Key Takeaways
- The Fed held rates steady at 5.25-5.5% as expected and emphasized that the economy is growing at a “strong pace”, inflation remains “elevated”, and the role of long-term yields in “tighter financial conditions”
- MacroX’s view that the hikes are done for the year got priced in more with the 2Y rallying 10 bps
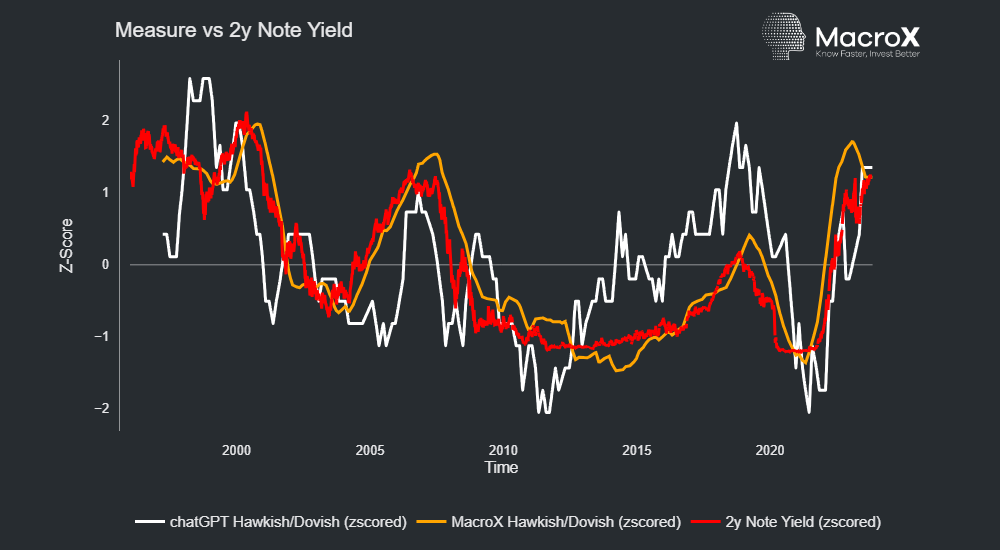
- Our Expert-trained LLM focused on macro does much better than a general model like chatGPT which interpreted yesterday’s statement as hawkish
The Fed held rates steady today at 5.25-5.5% as expected. The Fed acknowledged the US economy is growing at a “strong pace” (upgraded from “solid” in September) as inflation continues to “remain elevated”. However, they also acknowledged how the recent rise in long-term yields has caused “tighter financial conditions”. Many Fed observers had wondered if this tightening of conditions would Fed to skip the final hike they had signaled would occur by the end of the year in their September summary of economic projections – indeed, markets were only pricing c.30% chance of a further hike by the end of the year before the meeting. At MacroX, we have told our clients for a few weeks now that we think the Fed is done hiking for the rest of the year due to Core PCE likely underperforming Fed Sep projections and our interpretation of Fed communications. The Fed’s statement and Powell in his press conference did little to suggest a further hike was incoming, indeed market pricing of a further hike dropped to c.20% in the aftermath of the decision while the 2y yield dropped more than 10bps.
Much ink has been split over the advent of large language models (LLMs) and their potential use across industries. At the IIT conference we attended earlier this year, we heard from one of the authors of the original transformer paper, , who described how small “specialized” LLMs trained on proprietary data could be more useful for some tasks than the general LLMs we are more familiar with e.g. ChatGPT. Being able to diagnose central bank speak quickly and accurately as hawkish, neutral, or dovish can be extremely helpful when trading, and the existence of LLMs has made instantaneous scoring of Fed communications possible. But does a small “specialized” LLM work better than ChatGPT at this?
As a quick test, we decided to use the Fed’s statement today and see how MacroX’s internally trained LLM model of Fedspeak performed versus GPT3.5 and 4. Our model diagnosed the statement as “Neutral” whereas both versions of GPT diagnosed it as “Mostly Hawkish” showing that, at least in this instance, a specialized LLM did work better than a general one. Furthermore, when we looped the statement through the three models 100 times, MacroX’s model and GPT4 remained consistent in their diagnosis but this was not the case for GPT3.5 (see graph attached):
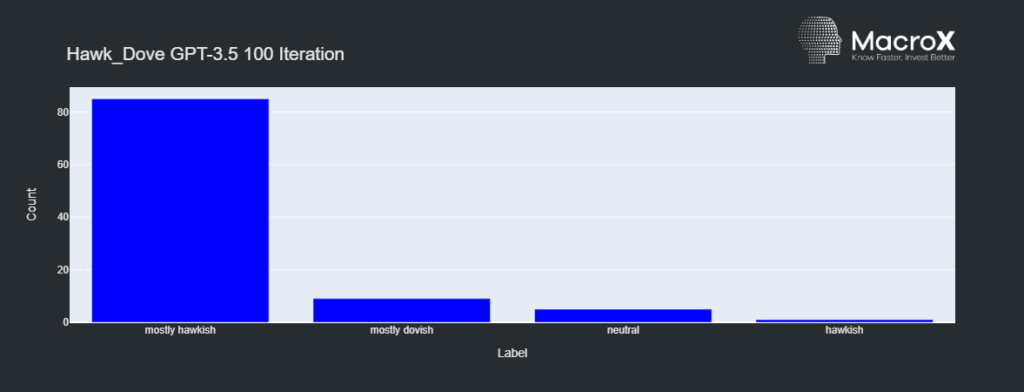
Therefore, if you’d traded based on GPT and gone short rates, you would have lost money but MacroX’s LLM interpreted the statement much more in line with the market!
This result holds more generally, as can seen below our model tracked the 2y yield much closer than GPT when looking at Fed communications over the past 25 years: